
Rha Overstreet - PharaohSun
Rha Overstreet Midterm Report
Fin 377 - Section 012 | Professor Bowen | Spring 2023
Report Code
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
df = pd.read_csv('output/analysis_sample.csv')
df = df.drop(['Unnamed: 0','_merge'], axis = 1)
#-----
p1 = pd.DataFrame()
p1 = df[['Symbol', 'BHR_pos_score', 'BHR_neg_score', 'LM_pos_score', 'LM_neg_score', 'portfolio_pos_score',
'portfolio_neg_score', 'project_pos_score', 'project_neg_score',
'capex_pos_score', 'capex_neg_score', 't_2', 't_3_10']]
#-----
p_lm = df[['LM_pos_score', 'LM_neg_score','t_2','BHR_pos_score', 'BHR_neg_score']]
1. Summary
In this study we compared stocks listed in the S&P500 to their stock prices after their 10-K (mandatory Securities and Exchange Commission) filling where published. The null-hypothesis for this study was “A companies stock price affected by the linguistic sentiment presented in the companies 10-K filing.” Linguistic sentiment was determined by 10 variables. 2 positive (negative) libraries created by Tim Loughran and Bill McDonald(LM), Diego Garcíaa, Xiaowen Hub, and Maximilian Rohrer(ML) respectivly, along with 3 positive (negative) categorical sentiment libraries created by myself. The sentiment score was determined by using a NEAR_regex function provided by our professor, which can be found in this project repository.
2. Data
The data sampled are the 500 firms listed within the S&P500. Throughout the study it was discovered that there was actually 503 symbols listed in the S&P500. By the end of the study, we where left with 496 observations. Within the S&P500 there are company’s who have stock splits and are therefore represented twice in the index. This is most notably observed with the google ticker symbols GOOG and GOOGL. Even though there are separate tickers the company only files one 10-K. Another drop in observations come from some companies in the S&P500 not having there 2022 10-K viewable on the SEC website for some reason. The other drop in observations comes from the stock returns list we used. BALL (and others) was listed in the S&P500, yet the correct dates where not present in the returns dataframe. We also used the CRSP Compustat Merged data to get accounting information on all of the firms in our final dataset.
Getting the compound returns </br>
In order to obtain the compound returns, a new column had to be created. This column would hold a variable called ‘adj_ret’ which stands for adjusted returns. The adjusted returns is simply adding one to the regular returns. Adding one to the regular returns, creates a normalized variable that becomes a multiplier. These multipliers can than be used as a product to generate the compounded returns of the holding period. </br>
Cumulative/Gross return = Product(Rt); t = 1,2,..,T
Choosing Sentiments </br>
The sentiment variables in the study where created by using the ‘NEAR_regex’ function provided to us by our professor. In order for the function to work, there needed to be clean comprehensive text to analyze and compare too. We started by creating a spider that crawled the SEC website and downloaded the 10-K fillings of the compatible S&P500 firms. Once these where found we downloaded, zipped the html files, and deleted the local files all at the same time. This method for downloading the files allowed us to work with a 179.4mb file rather than a few gb file. Once the files where zipped we used the os,bytes.io,zipfile, and pandas packages to open then. We cleaned the html files by removing the xml-lmxl tags, punctuation, and added white spaces to get the words in the document separated. Once the words where separated we where able to run a regex on them. </br>
There two classes of sentiments in this study. The first class are the NLP machine learning/finance libraries created by the authors mentioned in the abstract. These libraries where provided by our professor for this study. The second class of sentiments are the categorical sentiments created for this specific study by the researcher. </br>
The three categories chosen where: portfolio management, project risk, and capital expenditures. These libraries where built as both positive and negative sentiments. The key anchor words stayed the same in the positive and negative libraries while the search words are generally antonyms or sentiments that reflect positively (negatively) respectively when discussing the anchors. I choose these categories to understand how much asset management sentiment in 10-K’s affects the companies stock prices, or if they even have a causation at all.</br>
Final Summary Statistics
# Descriptive statistics
df.iloc[:,:16].describe()
| CIK | BHR_pos_score | BHR_neg_score | LM_pos_score | LM_neg_score | portfolio_pos_score | portfolio_neg_score | project_pos_score | project_neg_score | capex_pos_score | capex_neg_score | t_2 | t_3_10 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| count | 4.960000e+02 | 496.000000 | 496.000000 | 496.000000 | 496.000000 | 496.000000 | 496.000000 | 496.000000 | 496.000000 | 496.000000 | 496.000000 | 493.000000 | 493.000000 |
| mean | 7.921247e+05 | 0.023510 | 0.025476 | 0.004929 | 0.015821 | 0.002814 | 0.003269 | 0.005390 | 0.006697 | 0.005109 | 0.008814 | 0.003961 | -0.008787 |
| std | 5.525659e+05 | 0.004108 | 0.003692 | 0.001378 | 0.003886 | 0.000786 | 0.001106 | 0.000925 | 0.001315 | 0.001491 | 0.001684 | 0.044905 | 0.065878 |
| min | 1.800000e+03 | 0.003530 | 0.008953 | 0.000272 | 0.002541 | 0.000000 | 0.000000 | 0.002474 | 0.001271 | 0.001773 | 0.003536 | -0.447716 | -0.288483 |
| 25% | 9.767775e+04 | 0.021520 | 0.023554 | 0.004011 | 0.013240 | 0.002321 | 0.002591 | 0.004761 | 0.005981 | 0.004056 | 0.007717 | -0.019317 | -0.048646 |
| 50% | 8.840640e+05 | 0.023888 | 0.025689 | 0.004845 | 0.015546 | 0.002748 | 0.003093 | 0.005322 | 0.006785 | 0.004922 | 0.008691 | 0.000750 | -0.009661 |
| 75% | 1.137871e+06 | 0.025936 | 0.027566 | 0.005651 | 0.017897 | 0.003277 | 0.003760 | 0.005851 | 0.007470 | 0.005924 | 0.009611 | 0.026934 | 0.029412 |
| max | 1.868275e+06 | 0.037982 | 0.038030 | 0.010899 | 0.035088 | 0.005633 | 0.010827 | 0.009015 | 0.012292 | 0.011321 | 0.016639 | 0.369110 | 0.332299 |
In the S&P500 data set, there are 496 complete observations. </br> BHR Positive has the second largest mean sentiment score behind BHR Negative. This shows us that throughout the firms the BHR library has more sentiment hits. This makes sense due to the large size of this dictionary.
3. Results
# Correlation table with 10 variables and 2 returns
corr_plot = sns.heatmap(p1.corr(), cmap="YlGnBu", annot=True)
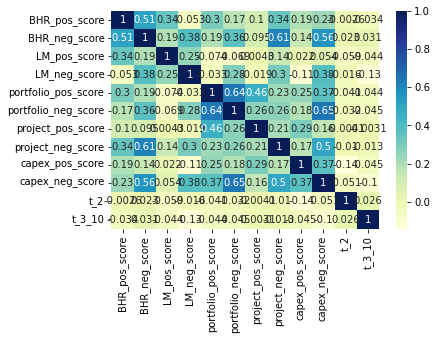
Discussion Question 1
It is interesting how the BHR sentiment scores have an inverse relationship to the returns. It appears that a positive BHR score is negatively correlated to the return. The LM scores are both negatively correlated to the holding period.
corr_lm = sns.heatmap(p_lm.corr(), annot=True)
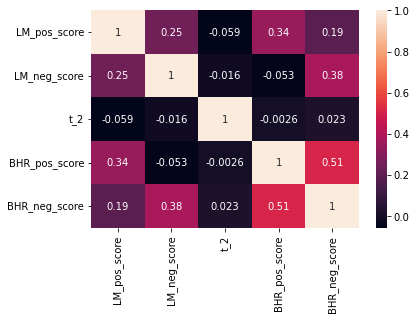
Discussion Question 2
With regards to table 3 in the ML_JFE paper, we are getting similar results. The correlation between the libraries is higher than the correlation between the libraries and the returns.
Discussion Question 3
I believe they decided to include so many more firms in their study for robustness. In a market with 3,000+ US participants and thousands more globally, to do a truly academic study, a large sample size is required. Large sample sizes decrease the probability of outliers and abnormalities affecting the results.
Discussion Question 4
There is a difference in magnitude in our results, I believe this is most likely due to their use of larger sentiment libraries and larger firm counts. The lack of correlation becomes marginally larger as the observation count increases.